Can i get 2d world coordinates from a single image ([u,v] coords)?
I'm new to everything vision!
I've read some similar posts but I can't get my head around it. Here's what I'm trying to do:
-I have a single camera looking down on a surface (we can assume it's normal to the surface) and I want to detect a hole and obtain it's [X,Y] from a world coordinate I have determined. -I do not care about the -Z info, I know the real hole diameter.
I have calibrated my camera and have the intrinsic matrix. For the extrinsic info I have taken 4 points from my image(mouse callback) and their correspondent 4-real points from the world coordinate to use 'solvePnP' and 'Rodrigues'(for the rotation matrix).
I can detect the hole using HoughCircles and I have the center in [u,v] coords.
Now, is there a way to obtain that [u,v] point in [X,Y] in my defined coordinate system???


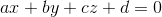

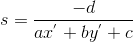


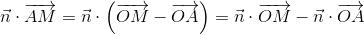

 with the quadruplet
with the quadruplet  .
.


{kind=link}
{kind=link}