Hi ,
I have lots of images in my dataset which looks like  (OCR libraries like tesseract is not able to OCR these images and printing gibberish)
(OCR libraries like tesseract is not able to OCR these images and printing gibberish)
applying some processing on above image I am able to improve it to something like 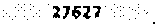 for which I am getting output through tesseract as 27837 "
for which I am getting output through tesseract as 27837 "
I have used the cv2.Thresh_Binary function with threshold value as 80 to make first image look like 2nd.( Median Blur ,Gaussian Blur, OTSU_binarisation , Morphological trasformations etc didn't worked in general for all images like these as character size is small and they make the images fizzy which again tesseract is not able to OCR ) transformed_img = cv2.threshold(input_img, 80,255, cv2.THRESH_BINARY)[1]
Can someone suggest a better method to treat these kind of images so that it can inturn improve the accuracy of OCR.
Thanks