I am implementing a paper on hierarchical superpixel clustering. The paper has this objective function that measures the similarity between 2 clusters.
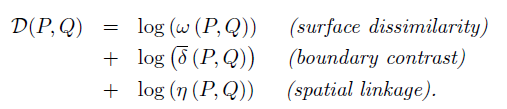
My question is, how do I determine the ideal weights for each term i.e. 5logw + 2logd + 1logn Do I have to run many iterations with random weights to see which works best ? Or is there a training method for this ?