@chamath, thank you for pointing an issue! The problem was in prior boxes generation (anchors).
Let's consider MultipleGridAnchorGenerator/concat_5 layer of MobileNet-SSD named as ssd_mobilenet_v1_coco_11_06_2017 (some old version) output is
[0.02500001 0.02500001 0.97500002 0.97500002] // min size
[0.01266029 0.01266029 0.98733974 0.98733974] // max size
[0.16412428 -0.17175144 0.83587575 1.1717515 ] // aspect ratio 2.0
[-0.17175144 0.16412428 1.1717515 0.83587575] // aspect ratio 0.5
[0.22575861 -0.3227241 0.77424139 1.3227241 ] // aspect ratio 3.0
[-0.32276523 0.22577232 1.32276523 0.77422768] // aspect ratio 0.333
OpenCV produces the following proposals at the corresponding layer:
[0.025 0.025 0.97500002 0.97500002] // min size
[0.01266027 0.01266027 0.98733968 0.98733968] // max size
[-0.17175145 0.16412427 1.1717515 0.83587575] // aspect ratio 2.0
[0.16412427 -0.17175145 0.83587575 1.1717515 ] // aspect ratio 0.5
[-0.3227241 0.22575861 1.3227241 0.77424139] // aspect ratio 3.0
[0.22575861 -0.32272416 0.77424139 1.32272422] // aspect ratio 0.333
Note that TensorFlow produces it in [ymin, xmin, ymax, xmax] order but OpenCV in [xmin, ymin, xmax, ymax]. OpenCV can manage it so it's OK.
OpenCV's PriorBox layer is based on origin Caffe-SSD framework (https://github.com/weiliu89/caffe/blo...). It produces anchors for min_size specified. Then for max_size and all the aspect ratios. It looks like TensorFlow followed this rule before some point.
Let's consider the same layers for your model. Perhaps, it was received from newer TensorFlow, right?
[0.02500001 0.02500001 0.97500002 0.97500002] // min size
[0.16412428 -0.17175144 0.83587575 1.1717515 ] // aspect ratio 2.0
[-0.17175144 0.16412428 1.1717515 0.83587575] // aspect ratio 0.5
[0.22575861 -0.3227241 0.77424139 1.3227241 ] // aspect ratio 3.0
[-0.32276523 0.22577232 1.32276523 0.77422768] // aspect ratio 0.333
[0.01266029 0.01266029 0.98733974 0.98733974] // max size
As you may see, anchor related to the max_size hyper-parameter moved to the bottom of the list. In short words, OpenCV for the same order of anchors (min-max-ratios) predicts deltas for an updated order (min-ratios-max).
To make it works properly please apply changes from PR https://github.com/opencv/opencv/pull... and use the following text graph: https://gist.github.com/dkurt/fb324b4...
Sample:
import numpy as np
import cv2 as cv
cvNet = cv.dnn.readNetFromTensorflow('hat_model/frozen_inference_graph.pb', 'ssd_mobilenet_v1_coco_hat.pbtxt')
img = cv.imread('/home/dkurtaev/Pictures/image5.jpg')
cvNet.setInput(cv.dnn.blobFromImage(img, 1.0/127.5, (300, 300), (127.5, 127.5, 127.5), swapRB=True, crop=False))
cvOut = cvNet.forward()
for detection in cvOut[0,0,:,:]:
score = float(detection[2])
if score > 0.5:
left = detection[3] * img.shape[1]
top = detection[4] * img.shape[0]
right = detection[5] * img.shape[1]
bottom = detection[6] * img.shape[0]
cv.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (0, 255, 0))
cv.imshow('img', img)
cv.waitKey ...
(more)
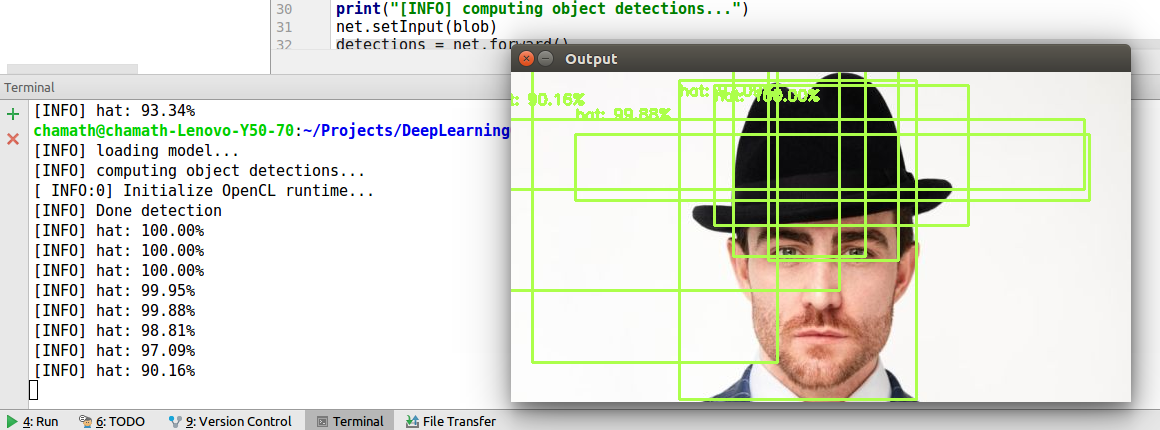
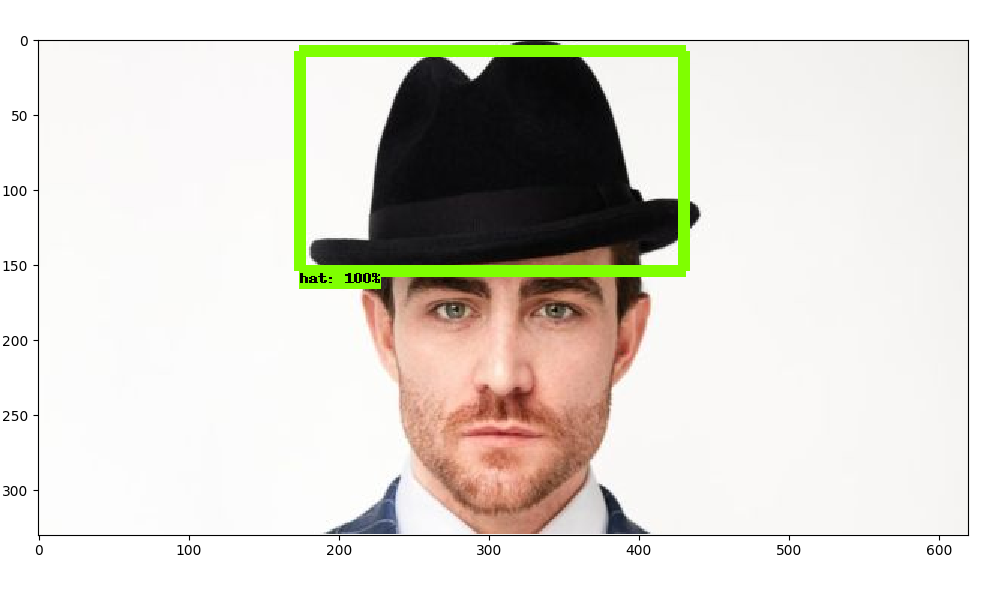

@chamath, what the difference between TensorFlow's MobileNet-SSD and yours? Number of classes is the same? Have you tried to run a sample https://github.com/opencv/opencv/blob... using your model? What input sizes did you use? Please share with us as much information as possible. At least an image with wrong predictions and code that draws them (if it isn't an OpenCV's sample code).
@dkurt, My opencv code is https://github.com/chamathabeysinghe/... . Number of classes are 1. I update the prototxt file's number of classes. I tested with the sample also. In video stream there is many squares as in the photo.
@chamath, thanks for the details! So you've changed
attr { key: "num_classes" value { i: 91 } }toattr { key: "num_classes" value { i: 2 } }, right? Please try to replacecv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), 127.5)tocv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), (127.5, 127.5, 127.5))because now it subtracts mean value only from blue channel.@dkurt, Yes I have changed num_classes. I made your change to image blob but still the issue is there.
If no more changes were made for model training (TensorFlow's config file), we need to know how you received a target image. Please share a code with TensorFlow model invocation.
Tensorflow code used for my model, https://gist.github.com/chamathabeysi.... This is exact copy from google object detection api https://github.com/tensorflow/models/... without model download part
@chamath, For training you've taken a config file, https://github.com/tensorflow/models/... and replaced only
num_classes: 1? Can you share a model?Yes for training replaced num_classes: 1 and PATH_TO_BE_CONFIGURED in the mentioned config file. Model is available in https://drive.google.com/file/d/1u_Hi... . My test images are available on https://github.com/chamathabeysinghe/...
@dkurt, any suggestions to solve this?
Any updates on this? Did you manage to make it work @chamath ?
I have the same problem, and from the issue-posts on github and here, I think the problem might be because of a mismatch between the config file used for retraining in the Object Detection API and the pbtxt-file used by Opencv.